python, natural language processing, keywords, nltk, hitchens, salinger, postman
To oversimplify, natural language processing is a set of strategies used by computers to interpret human language. Of course, this is just a blog post where you can follow along with my notes as I learn - this is by no means exhaustive.
Natural language processing was done using a symbolic approach in its advent ( implemented as hand written rules, circa 1960) - eventually statistical methods and neural methods were implemented and performed much better.
To get myself started, I will be using natural language processing in this blog post to extract keywords from some excerpts.
Python has an excellent natural language processing library called NLTK. NLTK stands for ‘natural language tool kit’. NLTK includes tools for the following computational linguistics concepts covered in this blog post:
stemming
The process of reducing a word to its root. For instance ‘describe’, ‘description’, and ‘describer’ all share ‘descri’.
tokenizing
Tokenisation is the process of turning a sentence into its component phrases, words, or subwords. For instance, in the case of subwords ‘antigravity’ might become ‘anti’ and ‘gravity’.
The following figure contains the example text to be processed in today’s post:
I thought what I’d do was, I’d pretend I was one of those deaf-mutes. That way I wouldn’t have to have any goddam stupid useless conversations with anybody. If anybody wanted to tell me something, they’d have to write it on a piece of paper and shove it over to me. They’d get bored as hell doing that after a while, and then I’d be through with having conversations for the rest of my life. Everybody’d think I was just a poor deaf-mute bastard and they’d leave me alone. I’d cook all my own food, and later on, if I wanted to get married or something, I’d meet this beautiful girl that was also a deaf-mute and we’d get married. She’d come and live in my cabin with me, and if she wanted to say anything to me, she’d have to write it on a piece of paper, like everybody else.
(a) Exercpt from The Catcher and the Rye, by J.D. Salinger used in the examples in these notes.
What Orwell feared were those who would ban books. What Huxley feared was that there would be no reason to ban a book, for there would be no one who wanted to read one. Orwell feared those who would deprive us of information. Huxley feared those who would give us so much that we would be reduced to passivity and egoism. Orwell feared that the truth would be concealed from us. Huxley feared the truth would be drowned in a sea of irrelevance. Orwell feared we would become a captive culture. Huxley feared we would become a trivial culture, preoccupied with some equivalent of the feelies, the orgy porgy, and the centrifugal bumblepuppy. As Huxley remarked in Brave New World Revisited, the civil libertarians and rationalists who are ever on the alert to oppose tyranny “failed to take into account man’s almost infinite appetite for distractions.” In 1984, Huxley added, people are controlled by inflicting pain. In Brave New World, they are controlled by inflicting pleasure. In short, Orwell feared that what we hate will ruin us. Huxley feared that what we love will ruin us.
(b) Exerpt from Amusing Ourselves to Death, by Niel Postman used in the examples in these notes.
We dwell in a present-tense culture that somehow, significantly, decided to employ the telling expression “You’re history” as a choice reprobation or insult, and thus elected to speak forgotten volumes about itself. By that standard, the forbidding dystopia of George Orwell’s Nineteen Eighty-Four already belongs, both as a text and as a date, with Ur and Mycenae, while the hedonist nihilism of Huxley still beckons toward a painless, amusement-sodden, and stress-free consensus. Orwell’s was a house of horrors. He seemed to strain credulity because he posited a regime that would go to any lengths to own and possess history, to rewrite and construct it, and to inculcate it by means of coercion. Whereas Huxley … rightly foresaw that any such regime could break because it could not bend. In 1988, four years after 1984, the Soviet Union scrapped its official history curriculum and announced that a newly authorized version was somewhere in the works. This was the precise moment when the regime conceded its own extinction. For true blissed-out and vacant servitude, though, you need an otherwise sophisticated society where no serious history is taught.
(c) Excerpt from Why Americans are not Taught History by Christopher Hitchens.
Figure 1
Setup
First we will need to import nltk and get some text to process. The piece of text I choose to use is from The Catcher and the Rye by J.D. Salinger.
import nltk.tokenizefrom acederbergio import db, utilimport pandas as pdfrom nltk.corpus import stopwordsnltk.download("punkt_tab")nltk.download("stopwords")# NOTE: From `The Catcher and the Rye` by `J.D. Salenger`.# Source: https://www.goodreads.com/quotes/629243-i-thought-what-i-d-do-was-i-d-pretend-i-wastext_salinger ="""I thought what I'd do was, I'd pretend I was one of those deaf-mutes. That way Iwouldn't have to have any goddam stupid useless conversations with anybody. Ifanybody wanted to tell me something, they'd have to write it on a piece of paperand shove it over to me. They'd get bored as hell doing that after a while, andthen I'd be through with having conversations for the rest of my life.Everybody'd think I was just a poor deaf-mute bastard and they'd leave me alone.I'd cook all my own food, and later on, if I wanted to get married orsomething, I'd meet this beautiful girl that was also a deaf-mute and we'd getmarried. She'd come and live in my cabin with me, and if she wanted to sayanything to me, she'd have to write it on a piece of paper, like everybody else""".strip().replace("\n", " ")# NOTE: From `Amusing Ourselves to Death`# Source: https://en.wikipedia.org/wiki/Amusing_Ourselves_to_Deathtext_postman ="""What Orwell feared were those who would ban books. What Huxley feared was thatthere would be no reason to ban a book, for there would be no one who wanted toread one. Orwell feared those who would deprive us of information. Huxleyfeared those who would give us so much that we would be reduced to passivityand egoism. Orwell feared that the truth would be concealed from us. Huxleyfeared the truth would be drowned in a sea of irrelevance. Orwell feared wewould become a captive culture. Huxley feared we would become a trivialculture, preoccupied with some equivalent of the feelies, the orgy porgy, andthe centrifugal bumblepuppy. As Huxley remarked in Brave New World Revisited,the civil libertarians and rationalists who are ever on the alert to opposetyranny "failed to take into account man's almost infinite appetite fordistractions." In 1984, Huxley added, people are controlled by inflicting pain.In Brave New World, they are controlled by inflicting pleasure. In short,Orwell feared that what we hate will ruin us. Huxley feared that what we lovewill ruin us.""".strip().replace("\n", " ")text_hitchens =""" We dwell in a present-tense culture that somehow, significantly, decided to employ the telling expression "You're history" as a choice reprobation or insult, and thus elected to speak forgotten volumes about itself. By that standard, the forbidding dystopia of George Orwell's Nineteen Eighty-Four already belongs, both as a text and as a date, with Ur and Mycenae, while the hedonist nihilism of Huxley still beckons toward a painless, amusement-sodden, and stress-free consensus. Orwell's was a house of horrors. He seemed to strain credulity because he posited a regime that would go to any lengths to own and possess history, to rewrite and construct it, and to inculcate it by means of coercion. Whereas Huxley ... rightly foresaw that any such regime could break because it could not bend. In 1988, four years after 1984, the Soviet Union scrapped its official history curriculum and announced that a newly authorized version was somewhere in the works. This was the precise moment when the regime conceded its own extinction. For true blissed-out and vacant servitude, though, you need an otherwise sophisticated society where no serious history is taught.""".strip().replace("\n", " ")
[nltk_data] Downloading package punkt_tab to /root/nltk_data...
[nltk_data] Unzipping tokenizers/punkt_tab.zip.
[nltk_data] Downloading package stopwords to /root/nltk_data...
[nltk_data] Unzipping corpora/stopwords.zip.
Tokenisation
Since tokenizing might be done at various scales, nltk provides a means to do both word and sentence tokenisation.
import rich.consoleimport iotokens_sent = nltk.tokenize.sent_tokenize(text_salinger)tokens_word = nltk.tokenize.word_tokenize(text_salinger)# NOTE: Use ``rich`` to put results into the terminal.console = rich.console.Console(record=True, width=100, file=io.StringIO())util.print_yaml(tokens_word[:10], rule_title="Word Tokens", console=console)util.print_yaml(tokens_sent, rule_title="Sentence Tokens", console=console)console.save_svg("./nlp-tokens-salinger.svg")
Figure 2: Word and sentence tokens extracted from @fig-quotes-salinger using nltks recommended tokenisation.
Tokenisation is pretty obvious in English due to the use of spaces. There are edge cases like abbreviations an ellipsis in sentence tokenisation and apostrophes in word tokenisation (notice that in Figure 1 (a) the word “I’d” is parsed as “I” and “’d” for instance). However, in languages like Arabic, Japanese and Chinese word tokenisation is not nearly as straight forward due to the lack of spaces.
The ‘Heart Sutra’, written in Japanese Calligraphy. Credit: TheArtOfCalligraphy.com
Stop Words
Certain words are not worth keeping during tokenisation for particular processes. For instance if one is looking for keywords, words like ‘is’, ‘the’, ‘if’ and so on should not be considered during tokenisation.
Conveniently, nltk provides a list of stop words. Stop words can be used in the tokenisation to enhance keyword finding:
The rapid automatic keyword extraction (RAKE) algorithm is a convenient means for extracting keywords from text. I will not go into implementation details today as my priority right now is to visualize results.
It exposes the Rake class to do keyword extraction and can be used to rank phrases. Using this method it is easy to throw together a dataframe ranking the various phrases found in some text.
Extraction Process
For my use-case, the same document will likely show up often. For this reason, I would like to save the output dataframe to MongoDB to save on runtime.
graph TD
InMongoDB[("`
Check *MongoDB* for Metrics
using **SHA256** of text.
`")]
InputText((Text is Input)) --> InMongoDB
InMongoDB -- Yes --> InMongoDBTrue[Return Stored Metrics]
InMongoDB -- No --> InMongoDBFalse[Compute New Metrics with Rake]
InMongoDBFalse -- SHA256 Label --> MongoDBSave[Save to MongoDB]
MongoDBSave --> Output{Pydantic Model}
InMongoDBTrue --> Output
Output --> Dataframe
Figure 4: Metric Generation Process.
DataFrame and Metrics Code
class MetricsRow(pydantic.BaseModel): phrase: str degree: float frequency: float ratio: float@classmethoddef fromDFRow(cls, row: pd.Series) -> Self:return cls.model_validate(dict(zip(MetricsColumns, row)))def to_df_row(self) ->tuple[str, float, float, float]:return (self.phrase, self.degree, self.frequency, self.ratio)class MetricsComparison(pydantic.BaseModel): phrases: Annotated[set[str], pydantic.Field(description="Common phrases.")] left: "Metrics" right: "Metrics" count_left: int score_left: Annotated[float, pydantic.Field(description="Percent containment of left in right."), ] count_right: int score_right: Annotated[float, pydantic.Field(description="Percent containerment of right in left."), ]@classmethoddef compare(cls, left: "Metrics", right: "Metrics") -> Self: phrases =set(left.metrics) &set(right.metrics) count_left =len(left.metrics) count_right =len(right.metrics)return cls( phrases=phrases, score_left=100*len(phrases) / count_left, score_right=100*len(phrases) / count_right, count_left=count_left, count_right=count_right, left=left, right=right, )class Metrics(util.HasTimestamp, db.HasMongoId):""" **RAKE** metrics for a piece of text. The goal is to put data into `MongoDB` and have this data be easily comparable to metrics for other documents. .. This should eventually use TLSH fuzzy hashes so similarity of documents can be clustered. For now, a ``sha_256`` hash is used to distinguish one document from another. :ivar text: The raw text for which the metrics are computed. :ivar metadata: Metadata. :ivar metrics: Key phrase metrics for :ivar:`text`. .. :ivar labels: Some labels for the data. """ _collection: ClassVar[str] ="metrics" text_hash_256: Annotated[str, pydantic.Field()] text: str metadata: dict[str, str] metrics: dict[str, MetricsRow]@pydantic.model_validator(mode="before")def compute_hashes(cls, v): hasher = hashlib.sha256() hasher.update(v["text"].encode()) v["text_hash_256"] = hasher.hexdigest()return v@classmethoddef createDFItem( cls, text: str, *, ranking_metric: rake.Metric, **rake_kwargs ) -> pd.DataFrame:if"include_repeated_phrases"notin rake_kwargs: rake_kwargs.update(include_repeated_phrases=False)# if "stopwords" not in rake_kwargs:# rake_kwargs.update(stopwords=MetricsStopWords) r = rake.Rake( language="english", ranking_metric=ranking_metric,**rake_kwargs, ) r.extract_keywords_from_text(text) q = {key: [value] for value, key in r.get_ranked_phrases_with_scores()}return pd.DataFrame(q)@classmethoddef createDF(cls, text: str, **rake_kwargs) -> pd.DataFrame:"""Create the dataframe from nothing. This should be compatible with the shape of `cls.metrics`. """ logger.info("Creating metrics dataframe.") df = pd.concat( [ cls.createDFItem(text, ranking_metric=ranking_metric, **rake_kwargs)for ranking_metric in rake.Metric ], ignore_index=True, ) df = df.transpose() # .rename(columns=[metric.name for metric in rake.]) df.reset_index(inplace=True) df.columns = MetricsColumns # type: ignore[assignment]return df@classmethoddef create( cls, df: pd.DataFrame, *, text: str, metadata: dict[str, str] |None=None ) -> Self:"""Transform a compatible dataframe into this object.""" metrics = {row[0]: MetricsRow.fromDFRow(row) for _, row in df.iterrows()}return cls(metrics=metrics, text=text, metadata=metadata) # type: ignore[call-arg,arg-type]@classmethoddef match_text(cls, text: str) ->dict:"""Match query against text digest.""" hasher = hashlib.sha256() hasher.update(text.encode())return {"$match": {"text_hash_256": hasher.hexdigest()}}@classmethodasyncdef fetch( cls, db: motor.motor_asyncio.AsyncIOMotorDatabase,*, text: str, ) -> Self |None: collection = db[cls._collection] res =await collection.find_one(cls.match_text(text)["$match"])if res isNone:returnNonereturn cls.model_validate(res)@classmethodasyncdef lazy( cls, db: motor.motor_asyncio.AsyncIOMotorDatabase,*, text: str, metadata: dict[str, str] |None=None, force: bool=False, ) -> Self:# if db is None:# return cls.create(cls.createDF(text), text=text, metadata=metadata) collection = db[cls._collection] res =await collection.find_one(cls.match_text(text)["$match"])ifnot force and res isnotNone: logger.info("Loading metrics dataframe from mongodb.") pydantic_data = cls.model_validate(res)else:if res isnotNoneand force: client = db[cls._collection] res =await client.delete_one({"_id": res["_id"]})ifnot res.deleted_count:raiseValueError("Failed to deleted object.") logger.info("Creating metrics dataframe since not found.") pydantic_data = cls.create(cls.createDF(text), text=text, metadata=metadata)await pydantic_data.store(db)return pydantic_dataasyncdef store(self, db: motor.motor_asyncio.AsyncIOMotorDatabase): logger.info("Saving metrics data to mongodb.") collection = db[self._collection] res =await collection.insert_one(self.model_dump(mode="json"))return resdef to_df(self) -> pd.DataFrame: rows = [value.to_df_row() for value inself.metrics.values()] df = pd.DataFrame(rows, columns=MetricsColumns)return dfdef trie(self) ->dict[str, Any]: root: dict[str, Any] = {}for phrase, metrics inself.metrics.items(): node = rootfor word in nltk.tokenize.word_tokenize(phrase):if word in node: node = node[word]else: node[word] = {} node = node[word]# NOTE: Terminal node contains data. node["__metrics__"] = metricsreturn rootdef chunks(self) -> Generator[dict[str, Any], None, None]: trie =self.trie() tokenized = nltk.tokenize.word_tokenize(self.text) k, n =0, len(tokenized) phrase: list[str] = []while k < n: word = tokenized[k] word_lower = word.lower() node = trie keyword = []while word_lower in node: keyword.append(word) node = node[word_lower] k +=1if k >= n:break word = tokenized[k] word_lower = word.lower()if keyword:if phrase:yield {"phrase": phrase} phrase =list()if"__metrics__"in node:yield {"match": "full","phrase": keyword,"metrics": node["__metrics__"], }else:yield {"match": "partial", "phrase": keyword} k +=1 phrase.append(word)if phrase:yield {"phrase": phrase}def highlight(self, highlighter: MetricsHighlighter |None=None) ->str:"""Return :ivar:`text` with the keywords highlighted using bold (as in markdown). Spaces are not perfect, but that is okay for now. The detokenizer does its best to fix everything up. """# NOTE: Probably faster to rebuild. This would be a good problem to# solve with a trie since phrases. detokenizer = nltk.TreebankWordDetokenizer() output = []for chunk inself.chunks(): match = chunk.get("match") metrics = chunk.get("metrics") phrase = detokenizer.detokenize(chunk["phrase"])if match isNone:passelif match =="full": phrase = (f"**{phrase}**"if highlighter isNoneelse highlighter(phrase, "full", metrics=metrics) )elif match =="partial": phrase = (f"*{phrase}*"if highlighter isNoneelse highlighter(phrase, "partial", metrics=metrics) )else:raiseValueError() output.append(phrase)return detokenizer.detokenize(output)def highlight_html(self,*, ranking_metric: rake.Metric = rake.Metric.DEGREE_TO_FREQUENCY_RATIO, ) ->str: ranking_attr = MetricsNamesMap[ranking_metric] value_max = (max((getattr(item, ranking_attr) for item inself.metrics.values())) //2 )# fmt: off colors = ["#2780e3", "#3e78e4", "#5571e5", "#6c6ae6", "#8362e7", "#9b5be8","#b254e9", "#c94cea", "#e045eb", "#f83eec", "#f00", ]# fmt: ondef highlighter(phrase: str, match: str, *, metrics: MetricsRow |None=None):if match =="partial":return phraseif metrics isnotNone: tooltip =f"ratio={metrics.ratio}, frequency={metrics.frequency}, degree={metrics.degree}."else: tooltip ="No metrics." value =getattr(metrics, ranking_attr) significance =min(math.floor(10* value / value_max), 10) color = colors[significance]returnf"""<text style='background: {color};' data-bs-toggle='tooltip' data-bs-title='{ tooltip }' class='fw-normal text-white' >{phrase}</text> """returnf"<div class='rake-highlights text-black fw-lighter pb-5'>{self.highlight(highlighter)}</div>"# def __and__(self, other: Self) -> dict[str, MetricsRow]:# """ """# phrases = [row.phrase for row in self.metrics if row.phrase in other.metrics]# def __xor__(self, other: Self): ...
Extraction Results
Asynchronous python Code in Jupyter Notebooks
Top level await is supported in jupyter notebooks. To any python user who mostly has experience outside of jupyter this looks quite strange, but it is supported in jupyter.
The following code puts the metrics (stored in pydantic models) into pandas dataframes. Then IPython is used to turn the tables into HTML.
from IPython import displaydisplay.display_html(metrics_salinger_df.head(10))display.display_html(metrics_postman_df.head(10))display.display_html(metrics_hitchens_df.head(10))
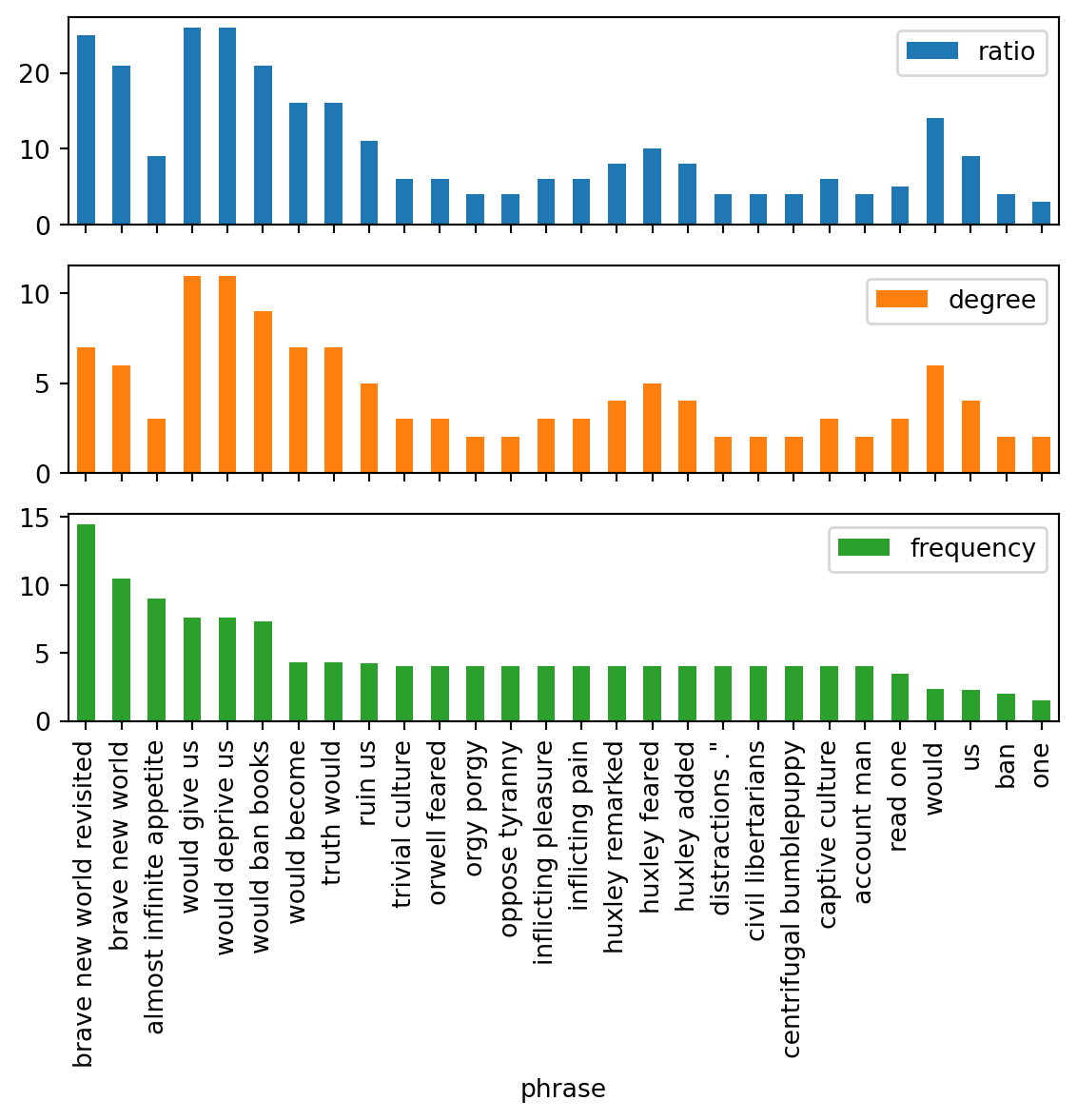
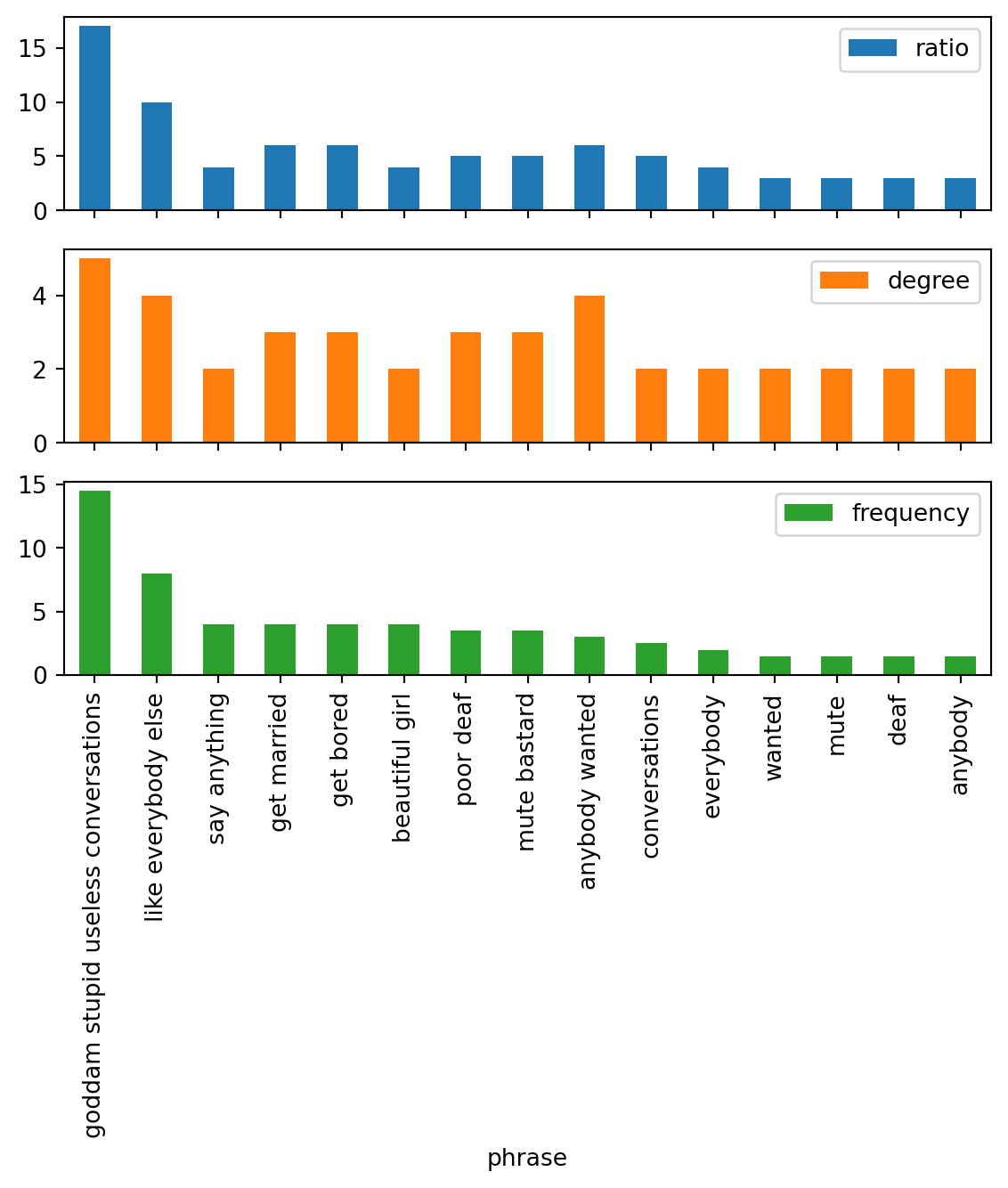
Figure 5: Metrics for the most common key phrases extracted from the texts shown in Figure 1 using each of the three separate metrics provided by nltk_rake.Metrics. This only includes the top ten key phrases output from each of the Rake analysis.
Using these tables, it is now possible to highlight the keywords. Highlighting is done by building a string trie of keywords and then matching the sentence against the trie. For small documents, the trie mostly branches at the root. The following blocks are the results of these analysis, and this is the code used to generate the figures to generate figures containing the texts with highlighted keywords and metrics charts.
def display_metrics_analysis(metrics: Metrics, metrics_df: pd.DataFrame):return display.display_html( display.HTML(metrics.highlight_html()), metrics_df.query("ratio > 1 and degree > 1 and frequency > 1") .set_index("phrase") .plot.bar( column=["ratio", "frequency", "degree"], subplots=True, title=[None, None, None], ), )
We dwell
in a present-tense culture that somehow
, significantly
, decided
to employ
the telling expression
"You're history
" as a choice reprobation
or insult
, and thus elected
to speak forgotten volumes
about itself . By that standard
, the forbidding dystopia
of George Orwell
's Nineteen Eighty-Four already belongs, both as a text
and as a date
, with Ur
and Mycenae
, while the hedonist nihilism
of Huxley still beckons toward
a painless
, amusement-sodden, and stress-free consensus. Orwell
's was a house
of horrors
. He seemed
to strain credulity
because he posited
a regime
that would go
to any lengths
to own and possess history
, to rewrite
and construct
it, and to inculcate
it by means
of coercion
. Whereas Huxley...rightly foresaw
that any such regime could break
because it could
not bend
. In 1988
, four years
after 1984
, the Soviet Union scrapped
its official history curriculum
and announced
that a newly authorized version
was somewhere
in the works
. This was the precise moment
when the regime conceded
its own extinction
. For true blissed-out and vacant servitude
, though
, you need
an otherwise sophisticated society
where no serious history
is taught
.
Figure 6: Figure 1 (c) highlights and metrics visualization.
What Orwell feared
were those who would ban books
. What Huxley feared
was that there would
be no reason
to ban
a book
, for there would
be no one
who wanted
to read one
. Orwell feared
those who would deprive us
of information
. Huxley feared
those who would give us
so much
that we would
be reduced
to passivity
and egoism
. Orwell feared
that the truth would
be concealed
from us
. Huxley feared
the truth would
be drowned
in a sea
of irrelevance
. Orwell feared
we would become
a captive culture
. Huxley feared
we would become
a trivial culture
, preoccupied
with some equivalent
of the feelies
, the orgy porgy
, and the centrifugal bumblepuppy
. As Huxley remarked
in Brave New World Revisited
, the civil libertarians
and rationalists
who are ever
on the alert
to oppose tyranny
" failed
to take
into account man
's almost infinite appetite
for distractions."
In 1984
, Huxley added
, people
are controlled
by inflicting pain
. In Brave New World
, they are controlled
by inflicting pleasure
. In short
, Orwell feared
that what we hate
will ruin us
. Huxley feared
that what we love
will ruin us
.
I thought
what I'd do was, I'd pretend
I was one
of those deaf-mutes . That way
I wouldn't have to have any goddam stupid useless conversations
with anybody
. If anybody wanted
to tell
me something
, they'd have to write
it on a piece
of paper
and shove
it over to me . They'd get bored
as hell
doing that after a while, and then I'd be through with having conversations
for the rest
of my life
. Everybody
'd think
I was just a poor deaf-mute bastard and they'd leave
me alone
. I'd cook
all my own food
, and later
on, if I wanted
to get married
or something
, I'd meet
this beautiful girl
that was also
a deaf-mute and we'd get married
. She'd come
and live
in my cabin
with me, and if she wanted
to say anything
to me, she'd have to write
it on a piece
of paper
, like everybody else
else
Figure 8: Figure 1 (a) highlights and metrics visualization.